
Grouping to a ConcurrentMap
If the collector returned by the Collectors.groupingBy() method is used in a parallel stream, the partial maps created during execution are merged to create the final map—as in the case of the Collectors.toMap() method (p. 983). Merging maps can carry a performance penalty. The Collectors class provides the three groupingBy-Concurrent() overloaded methods, analogous to the three groupingBy() methods, that return a concurrent collector—that is, a collector that uses a single concurrent map to perform the reduction. The entries in such a map are unordered. A concurrent map implements the java.util.concurrent.ConcurrentMap interface (§23.7, p. 1482).
Usage of the groupingByConcurrent() method is illustrated by the following example of a parallel stream to create a concurrent map of the number of CDs that have the same number of tracks.
ConcurrentMap<Integer, Long> map66 = CD.cdList
.parallelStream()
.collect(Collectors.groupingByConcurrent(CD::noOfTracks,
Collectors.counting()));
//{6=1, 8=2, 10=2}
Partitioning
Partitioning is a special case of grouping. The classifier function that was used for grouping is now a partitioning predicate in the partitioningBy() method. The predicate function returns the boolean value true or false. As the keys of the resulting map are determined by the classifier function, the keys are determined by the partitioning predicate in the case of partitioning. Thus the keys are always of type Boolean, implying that the classification map can have, at most, two map entries. In other words, the partitioningBy() method can only create, at most, two partitions from the input elements. The map value associated with a key in the resulting map is managed by a downstream collector, as in the case of the groupingBy() method.
There are two versions of the partitioningBy() method:
static <T> Collector<T,?,Map<Boolean,List<T>>> partitioningBy(
Predicate<? super T> predicate)
static <T,D,A> Collector<T,?,Map<Boolean,D>> partitioningBy(
Predicate<? super T> predicate,
Collector<? super T,A,D> downstream)
The collector returned by the first method produces a classification map of type Map<Boolean, List<T>>. The keys in this map are the results from applying the partitioning predicate to the input elements. The input elements that map to the same Boolean key are accumulated into a List by the default downstream collector Collector.toList().
The second method accepts a downstream collector, in addition to the partitioning predicate. The collector returned by the method is composed with the specified downstream collector that performs a reduction operation on the input elements that map to the same key. It operates on elements of type T and produces a result of type D. The result of type D produced by the downstream collector is the value associated with the key of type Boolean. The composed collector thus results in a resulting map of type Map<Boolean, D>.
Figure 16.18 illustrates the partitioningBy() operation by partitioning CDs according to the predicate CD::isPop that determines whether a CD is a pop music CD. The result of the partitioning predicate acts as the key in the resulting map of type Map<Boolean, List<CD>>. Since the call to the partitioningBy() method in Figure 16.18 does not specify a downstream collector, the default downstream collector Collector.toList() is used to accumulate CDs that map to the same key. The resulting map has two entries or partitions: one for CDs that are pop music CDs and one for CDs that are not. The two entries of the resulting map are also shown below:
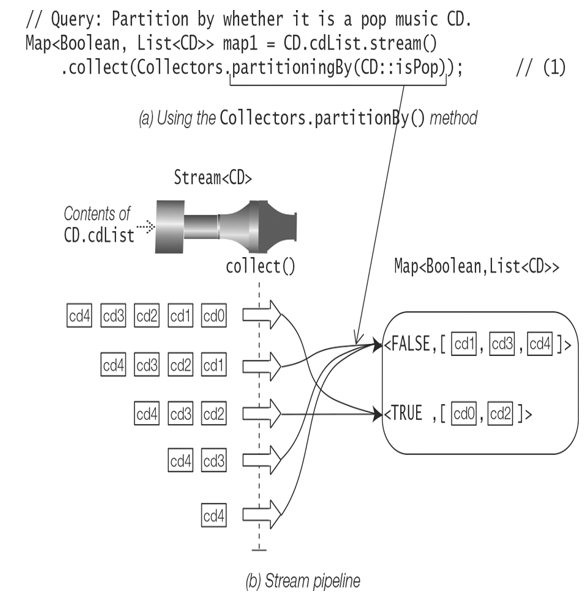
Figure 16.18 Partitioning
{false=[<Jaav, “Java Jam”, 6, 2017, JAZZ>,
<Genericos, “Keep on Erasing”, 8, 2018, JAZZ>,
<Genericos, “Hot Generics”, 10, 2018, JAZZ>],
true=[<Jaav, “Java Jive”, 8, 2017, POP>,
<Funkies, “Lambda Dancing”, 10, 2018, POP>]}
The values in a partition can be obtained by calling the Map.get() method:
List<CD> popCDs = map1.get(true);
List<CD> nonPopCDs = map1.get(false);
The stream pipeline at (2) is equivalent to the one in Figure 16.18, where the downstream collector is specified explicitly.
Map<Boolean, List<CD>> map2 = CD.cdList.stream()
.collect(Collectors.partitioningBy(CD::isPop, Collectors.toList())); // (2)
We could have composed a stream pipeline to filter the CDs that are pop music CDs and collected them into a list. We would have to compose a second pipeline to find the CDs that are not pop music CDs. However, the partitioningBy() method does both in a single operation.
Analogous to the groupingBy() method, any collector can be passed as a downstream collector to the partitioningBy() method. In the stream pipeline below, the downstream collector Collector.counting() performs a functional reduction to count the number of CDs associated with a key (p. 998).
Map<Boolean, Long> map3 = CD.cdList.stream()
.collect(Collectors.partitioningBy(CD::isPop, Collectors.counting()));
//{false=3, true=2}