
Multilevel Grouping
The downstream collector in a groupingBy() operation can be created by another groupingBy() operation, resulting in a multilevel grouping operation—also known as a multilevel classification or cascaded grouping operation. We can extend the multilevel groupingBy() operation to any number of levels by making the downstream collector be a groupingBy() operation.
The stream pipeline below creates a classification map in which the CDs are first grouped by the number of tracks in a CD at (1), and then grouped by the musical genre of a CD at (2).
Map<Integer, Map<Genre, List<CD>>> twoLevelGrp = CD.cdList.stream()
.collect(Collectors.groupingBy(CD::noOfTracks, // (1)
Collectors.groupingBy(CD::genre))); // (2)
Printing the contents of the resulting classification map would show the following three entries, not necessarily in this order:
{
6={JAZZ=[<Jaav, “Java Jam”, 6, 2017, JAZZ>]},
8={JAZZ=[<Genericos, “Keep on Erasing”, 8, 2018, JAZZ>],
POP=[<Jaav, “Java Jive”, 8, 2017, POP>]},
10={JAZZ=[<Genericos, “Hot Generics”, 10, 2018, JAZZ>],
POP=[<Funkies, “Lambda Dancing”, 10, 2018, POP>]}
}
The entries of the resulting classification map can also be illustrated as a two-dimensional matrix, as shown in Figure 16.16, where the CDs are first grouped into rows by the number of tracks, and then grouped into columns by the musical genre. The value of an element in the matrix is a list of CDs which have the same number of tracks (row) and the same musical genre (column).
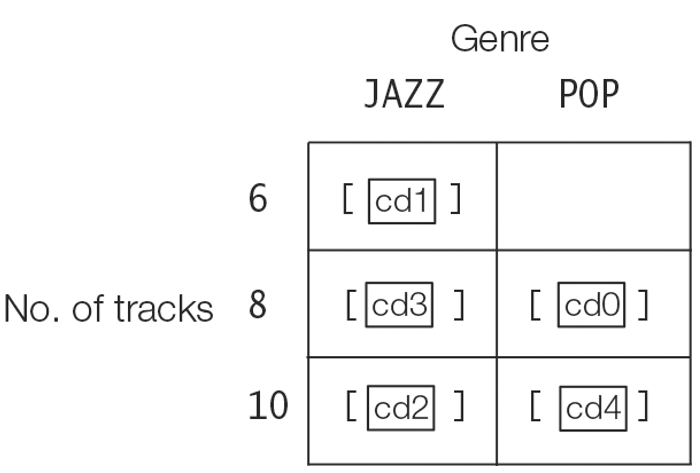
Figure 16.17 Multilevel Grouping as a Two-Dimensional Matrix
The number of groups in the classification map returned by the above pipeline is equal to the number of distinct values for the number of tracks, as in the single-level groupingBy() operation. However, each value associated with a key in the outer classification map is now an inner classification map that is managed by the second-level groupingBy() operation. The inner classification map has the type Map<Genre, List<CD>>; in other words, the key in the inner classification map is the musical genre of the CD and the value associated with this key is a List of CDs with this musical genre. It is the second-level groupingBy() operation that is responsible for grouping each CD in the inner classification map. Since no explicit downstream collector is specified for the second-level groupingBy() operation, it uses the default downstream collector Collector.toList().
We can modify the multilevel groupingBy() operation to count the CDs that have the same musical genre and the same number of tracks by specifying an explicit downstream collector for the second-level groupingBy() operation, as shown at (3).
The collector Collectors.counting() at (3) performs a functional reduction by accumulating the count for CDs with the same number of tracks and the same musical genre in the inner classification map (p. 998).
Map<Integer, Map<Genre, Long>> twoLevelGrp2 = CD.cdList.stream()
.collect(Collectors.groupingBy(CD::noOfTracks,
Collectors.groupingBy(CD::genre,
Collectors.counting()))); // (3)
Printing the contents of the resulting classification map produced by this multilevel groupingBy() operation would show the following three entries, again not necessarily in this order:
{6={JAZZ=1}, 8={JAZZ=1, POP=1}, 10={JAZZ=1, POP=1}}
It is instructive to compare the entries in the resulting classification maps in the two examples illustrated here.
To truly appreciate the groupingBy() operation, the reader is highly encouraged to implement the multilevel grouping examples in an imperative style, without using the Stream API. Good luck!